深入理解shortcut |
您所在的位置:网站首页 › shortcut maker汉化 › 深入理解shortcut |
深入理解shortcut
|
概述
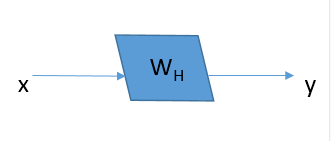
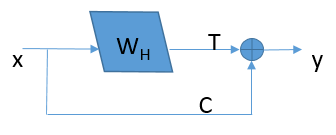
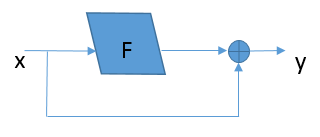
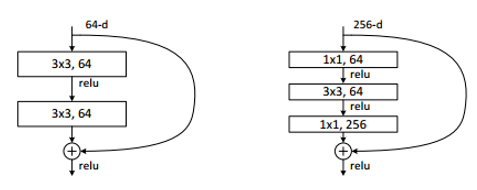
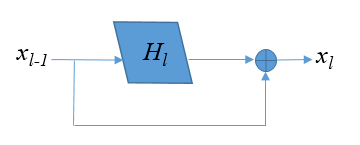
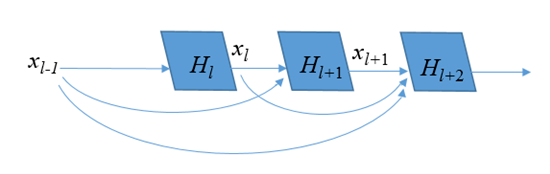
shortcut(或shortpath,中文“直连”或“捷径”)是CNN模型发展中出现的一种非常有效的结构,本文将从Highway networks到ResNet再到DenseNet概述shortcut的发展。 前言自2012年Alex Krizhevsky利用深度卷积神经网络(CNN)(AlexNet )取得ImageNet比赛冠军起,CNN在计算机视觉方面的应用引起了大家广泛地讨论与研究,也涌现了一大批优秀的CNN模型。研究人员发现,网络的深度对CNN的效果影响非常大,但是单纯地增加网络深度并不能简单地提高网络的效果,由于梯度发散,反而可能损害模型的效果。而shortcut的引入就是解决这个问题的妙招。本文主要就模型发展中的shortcut展开讨论。 1. Highway networksHighway 是较早将shortcut的思想引入深度模型中一种方法,目的就是为了解决深度网络中梯度发散,难以训练的问题。我们知道,对于最初的CNN模型(称为“plain networks”,并不特指某个模型框架),只有相邻两层之间存在连接,如图1所示,x、y是相邻两层,通过W_H连接,通过将多个这样的层前后串接起来就形成了深度网络。相邻层之间的关系如下, 网络变化如下图: 为了解决深度网络的梯度发散问题,Highway在两层之间增加了(带权的)shortcut。两层之间的结构如图所示。 关系式如下: 其中设置C=1-T,可以将上式改写为: 文中作者将T称为“transform gate”,将C称为“carry gate”。输入层x是通过C的加权连接到输出层y。通过这种连接方式的改进,缓解了深度网络中的梯度发散问题。 2.ResNetResNet的动机依然是解决深度模型中的退化问题:层数越深,梯度越容易发散,误差越大,难以训练。理论上,模型层数越深,误差应该越小才对,因为我们总可以根据浅层模型的解构造出深层模型的解(将深层模型与浅层模型对应的层赋值为浅层模型的权重,将后面的层取为恒等映射),使得这个深层模型的误差不大于浅层模型的误差。但是实际上,深度模型的误差要比浅层模型的误差要大, 作者认为产生这种现象的原因是深度模型难以优化,难以收敛到较优的解,并假设相比于直接优化最初的plain networks的模型F(x)=y,残差F(x)=y-x更容易优化。 对于ResNet,形式化地表示为下图,优化的目标F为F(x)=y-x,即为残差。 需要注意的是,变换F可以是很多层,也就是说shortcut不一定只跨越1层。并且实际中,由于shortcut只跨越单层没有优势,ResNet中是跨越了2层或3层。ResNet-34中,采用下图左侧的shortcut跨越方式;ResNet-50/101/152采用下图右侧的shortcut跨越方式。 对比highway networks和plain networks,可以看到ResNet的改进主要在以下方面: 将highway networks的T和C都设为1,降低模型的自由度(深度模型中,自由度越大未必越好。自由度越大,训练会比较困难)。shortcut不仅限于跨越1层,而可以跨越2层或3层。 三、DenseNetDenseNet 的初衷依然是为了解决深度模型的退化问题——梯度发散,借鉴highway networks和ResNet的思路,DenseNet将shortcut用到了“极致”——每两层之间都添加shortcut,L层的网络共有L*(L-1)/2个shortcut(如果我们这样做模型会不会太大?参数会不会太多?计算会不会太慢?作者当然不会直接这么做)。通过shortcut可以直接将浅层的信息传递到深层,一方面可以解决退化问题,另一方面也可以看作是特征重用(feature reuse)。 对于ResNet,相邻两层之间有: 对于DenseNet,则有 : 连接单元如下图所示,每层的输出结果都会通过shortcut连接到后面的层。 如果真的每层的输出都稠密地连接到后面的所有层,那么模型将变得非常“宽”,计算将会很慢。因此,作者采用的是“局部”稠密连接,如下图所示,每个block里面才进行稠密连接。每个block里面的连接方式如下图所示,前面层的输出通过shortcut直接连接到block中后面的其他层。block之间通过transition层连接。 对于一个包括t层的block,假设每层输出k个feature map(或通道),则第i(1 ≤i≤ t)层的输入feature map数为k*(i-1)+k0,其中k0为block的输入的通道数。将层分block只是限制了i的大小,如果每层的输出数k比较大的话,计算仍然很慢,因此作者也对k进行了限制,文中k称为growth rate。此外为了将模型进一步压缩,作者还采用了bottleneck layer和对transition的输出进行压缩(DenseNet-BC)。 转载自https://cloud.tencent.com/developer/article/1148375 |

【本文地址】
今日新闻 |
推荐新闻 |